One of the Largest AWS Outages Ever
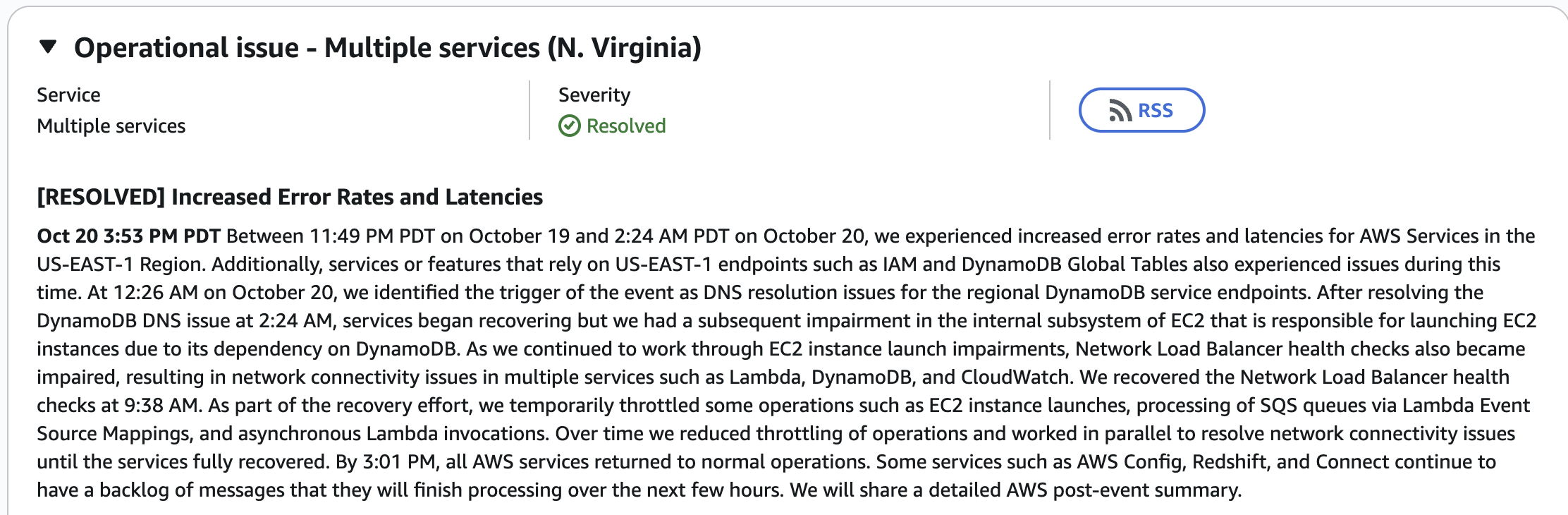
Le 20 octobre 2025 à 00h11 PDT, AWS commence son enquête sur des erreurs et latences dans la région US-EAST-1 — la plus grande et la plus ancienne région AWS.
La cascade
À 1h26 PDT : erreurs massives sur DynamoDB. En cascade : Lambda, SQS, le système de contrôle EC2 et les API gateways tombent. Cause identifiée : « problème de résolution DNS de l'endpoint DynamoDB ». À 3h35 PDT : « Le problème DNS a été entièrement résolu » — mais les erreurs EC2 persistent.
Impact
Snapchat, Venmo, Reddit et pratiquement tous les clients AWS connaissent des interruptions. AWS a bridé les nouveaux lancements EC2 pour stabiliser le réseau. Rétablissement progressif en fin d'après-midi.

Estimation des pertes : plus d'un milliard de dollars. La plus grande panne Internet depuis l'incident CrowdStrike de 2024.
Article original : vxdb.sh
Retour au portfolio